





반응형
반응형
이번에는 제가 원하는 정적으로 동작하는 웹 사이트에서 제품명, 제품유형, 제조사, 인증일, 인증만료일 등 데이터를 추출하는 프로그램을 파이썬으로 구현해보았습니다.
항상 크롤링에서 중요한 것은, 파싱하고자 하는 웹 사이트의 HTML에서 원하는 경로를 바로 파악하는 능력이 필요하다고 생각합니다.
(내가 원하는 데이터가 어떤 div 태그영역에 있는지 확인하고, div 태그 내에서 class 값 또는 id 값 등을 이용해 해당 데이터를 추출할 수 있는지가 필요)
아래는 제가 원하는 사이트에서 html 내 태그값을 이용하여 제품명, 분류, 제조사, 인증일, 인증만료일, 상태값을 추출하는 코드입니다.
import requests, openpyxl
from bs4 import BeautifulSoup
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(["제품명", "분류", "제조사", "인증일", "인증만료일", "상태값"])
#크롤링할 사이트 직접입력하였으며, URL 변수로 별도 선언 후 input() 을 통해 크롤링할 URL을 입력받도록 만들어도 됨.
for i in range(1, 10+1, 1):
raw = requests.get(
"https://www.bsi.bund.de/SiteGlobals/Forms/IT-Sicherheitskennzeichen/EN/IT-Sicherheitskennzeichen_Formular.html?gtp=980004_list%253D{}".format(
(i)))
html = BeautifulSoup(raw.text, 'html.parser')
#크롤링 할 영역을 container로 저장
container = html.select(".c-search-results > ul > li")
for c in container:
#제품명 추출
product_name = c.select_one(".c-search-result-teaser__headline").text.strip()
#본문(카테고리, 제조사, 인증일, 인증만료일)의 데이터를 추출하여 line별로 list에 저장
product_data = c.select_one(".c-search-result-teaser__content").text.strip()
product_data_list = product_data.splitlines()
#리스트로부터 제품의 카테고리, 제조사, 인증일, 인증만료일 데이터를 추출
category = product_data_list[0].replace("Category: ", "")
manufacturer = product_data_list[1].replace("Manufacturer: ", "")
Date_of_issue = product_data_list[2].replace("Date of issue: ", "")
end_of_term = product_data_list[3].replace("End of term: ", "")
#제품의 상태값은 해당 제품들의 링크로 들어가서 추출해야하므로, 링크값(a태그) 추출 후, 한번 더 BeautifulSoup를 이용해 Status 값을 추출
product_status_link = c.find('a')['href']
raw_status = requests.get('https://www.bsi.bund.de/' + product_status_link)
html_status = BeautifulSoup(raw_status.text, 'html.parser')
product_status = html_status.select_one('.c-product-stage__security-status').text.strip()
#엑셀 시트에 저장
sheet.append([product_name, category, manufacturer, Date_of_issue, end_of_term, product_status])
wb.save("C:/Users/user/Documents/bsi_product_search.xlsx")
결과
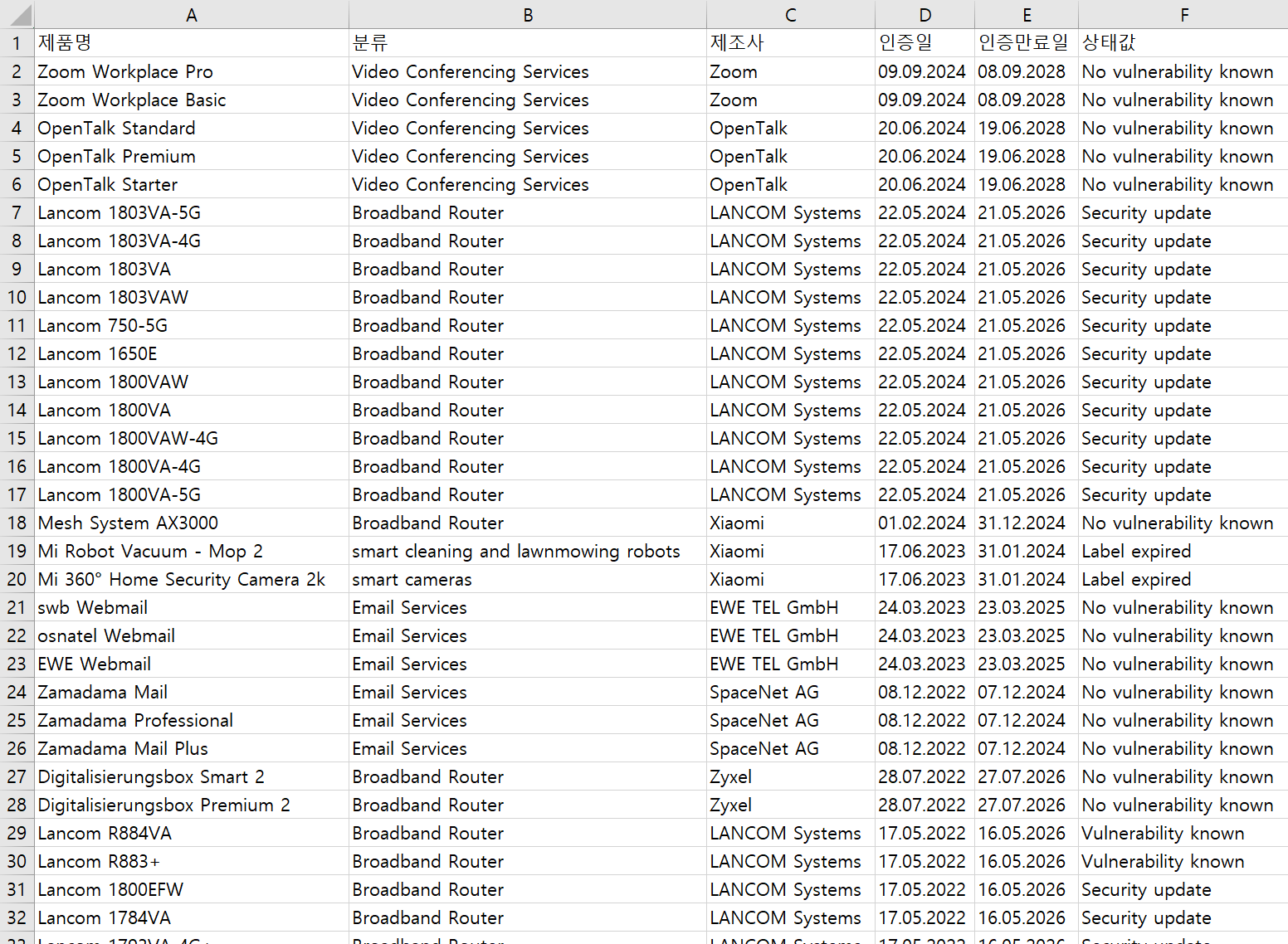
위 코드에서 포인트는 A웹사이트에서, A->A' 사이트(A'는 각 제품의 상세페이지)로 한번 더 들어가서 제품의 현재 상태값(status)을 추출해주는 부분입니다.
각 제품들의 링크로 들어가서 한번 더 beautifulsoup를 이용해 파싱하고, 상태값을 불러오는 부분에서 상당한 딜레이가 발생하는 것을 확인하였습니다.
어떻게 성능을 개선할지가 다음 과제인것 같습니다.
좋은 의견 있으실 경우 남겨주시면 언제든 환영입니다.
반응형
'Programming > Python' 카테고리의 다른 글
| 내가 만든 파이썬 프로그램을 누구나 사용할 수 있도록 실행파일로 생성하기 (1) | 2024.09.18 |
|---|---|
| Sorting(7) Merge Sort(합병 정렬) (0) | 2016.10.27 |
| Sorting(6) Heap Sort(힙 정렬 - max heap) (0) | 2016.10.27 |
| Sorting(5) Heap Sort(힙 정렬 - min Heap) (0) | 2016.10.27 |
| Sorting(4) Selection Sort(선택 정렬) (0) | 2016.10.27 |
WRITTEN BY
,